1.0 | Introduction
In modern logistics, efficient freight booking is crucial for both cost-effectiveness and sustainability. However, warehouse freight bookers often lack the time to compare different shipping options, leading to suboptimal decisions regarding delivery performance, sustainability, and pricing.
This project focuses on improving the accuracy of estimated time of arrival (ETA) predictions in logistics. The predictive machine learning model was developed in KNIME. It offers better delivery estimates, meaning that it is more precise in specifying the actual date of delivery. The host of the project, its project owner was TKL Logistics.
For a detailed breakdown of our work, you can access the full project report here: Download Report.
2.0 | Methodology
To structure our approach, we followed the CRISP-DM (Cross-Industry Standard Process for Data Mining) framework. This provided a systematic workflow from business understanding to deployment.
Our data included shipment details such as origin and destination countries, transportation means, cost, CO2 emissions, distance, delivery agents, and historical performance. After preprocessing, which involved one-hot encoding categorical variables, removing irrelevant attributes, handling missing data, and applying normalization techniques, we built predictive models.
We chose Gradient Boosted Trees as our primary regression model due to its superior performance in Mean Absolute Error (MAE) and Mean Absolute Percentage Error (MAPE). The model was fine-tuned separately for different transportation modes to improve accuracy.
3.0 | Results & Analysis
Our initial model, trained on all shipment data together, achieved an R² of 0.9. However, breaking it down by transportation mode resulted in substantially lower but more realistic values (0.2-0.5). Evaluating using MAE, MAPE, and custom error bounds showed significant improvements over traditional heuristics.
The figure below highlights the bird’s-eye structural view of our final model.
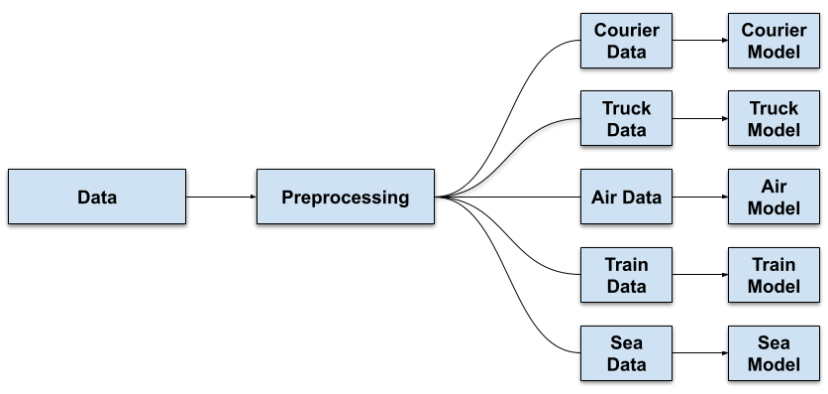
Our model reduced ETA prediction error across multiple transportation methods. Below I highlight the improvement that our model delivers by comparing it to their (at that time) static baselines. The comparison is using the mean-absolute-error (MAE).
- Sea: MAE decreased from
6.706to4.581days. - Train: MAE decreased from
4.433to2.464days. - Truck: MAE decreased from
1.114to0.867days. - Air: MAE decreased from
1.690to0.942days. - Courier: MAE decreased from
2.509to1.213days.
The model still has room for improvement through the consideration of features that are of high relevancy to prediction of ETA.Especially in unpredictable environments, such as courier deliveries. Long deliveries also missed important features, such as delays of various kinds. A rigourious analysis of the most relevant factors for ETA prediction is desirable. Nonetheless, the results do in fact highlight that AI-driven models significantly outperform static baselines. Our machine learning model outperforms their baseline in all cases.
4.0 | Conclusion & Future Work
This project highlights how data science can drive better decision-making in logistics. The results show that predictive models can reduce ETA uncertainty and provide smarter freight booking recommendations.
Looking ahead, the model could be further refined by integrating real-time traffic and weather data, enhancing data granularity with route-based scheduling patterns, and collaborating with shipping agents to improve dataset richness.